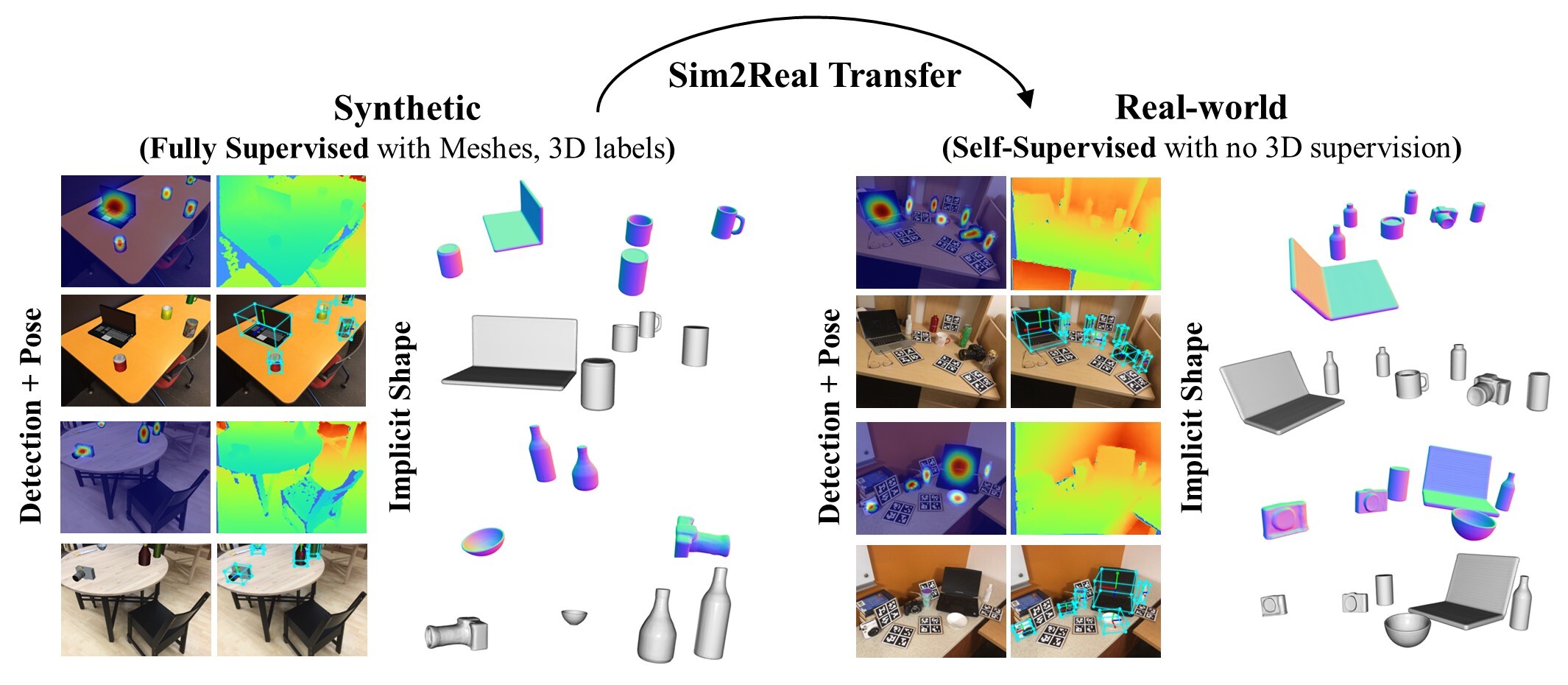
We present FSD: a fast self-supervised categorical 6D pose and size estimation and shape reconstruction framework. Our method is a fully feed-forward approach that doesn’t require any real-world 3D labels such as meshes or 6D pose annotations and it does not necessitate inference time optimization.
Abstract
In this work, we address the challenging task of 3D object recognition without the reliance on real-world 3D labeled data. Our goal is to predict the 3D shape, size, and 6D pose of objects within a single RGB-D image, operating at the category level and eliminating the need for CAD models during inference.
While existing self-supervised methods have made strides in this field, they often suffer from inefficiencies arising from non-end-to-end processing, reliance on separate models for different object categories, and slow surface extraction during the training of implicit reconstruction models; thus hindering both the speed and real-world applicability of the 3D recognition process. Our proposed method leverages a multi-stage training pipeline, designed to efficiently transfer synthetic performance to the real-world domain. This approach is achieved through a combination of 2D and 3D supervised losses during the synthetic domain training, followed by the incorporation of 2D supervised and 3D self-supervised losses on real-world data in two additional learning stages.
By adopting this comprehensive strategy, our method successfully overcomes the aforementioned limitations and outperforms existing self- supervised 6D pose and size estimation baselines on the NOCS test-set with a 16.4% absolute improvement in mAP for 6D pose estimation while running in near real-time at 5 Hz
Method
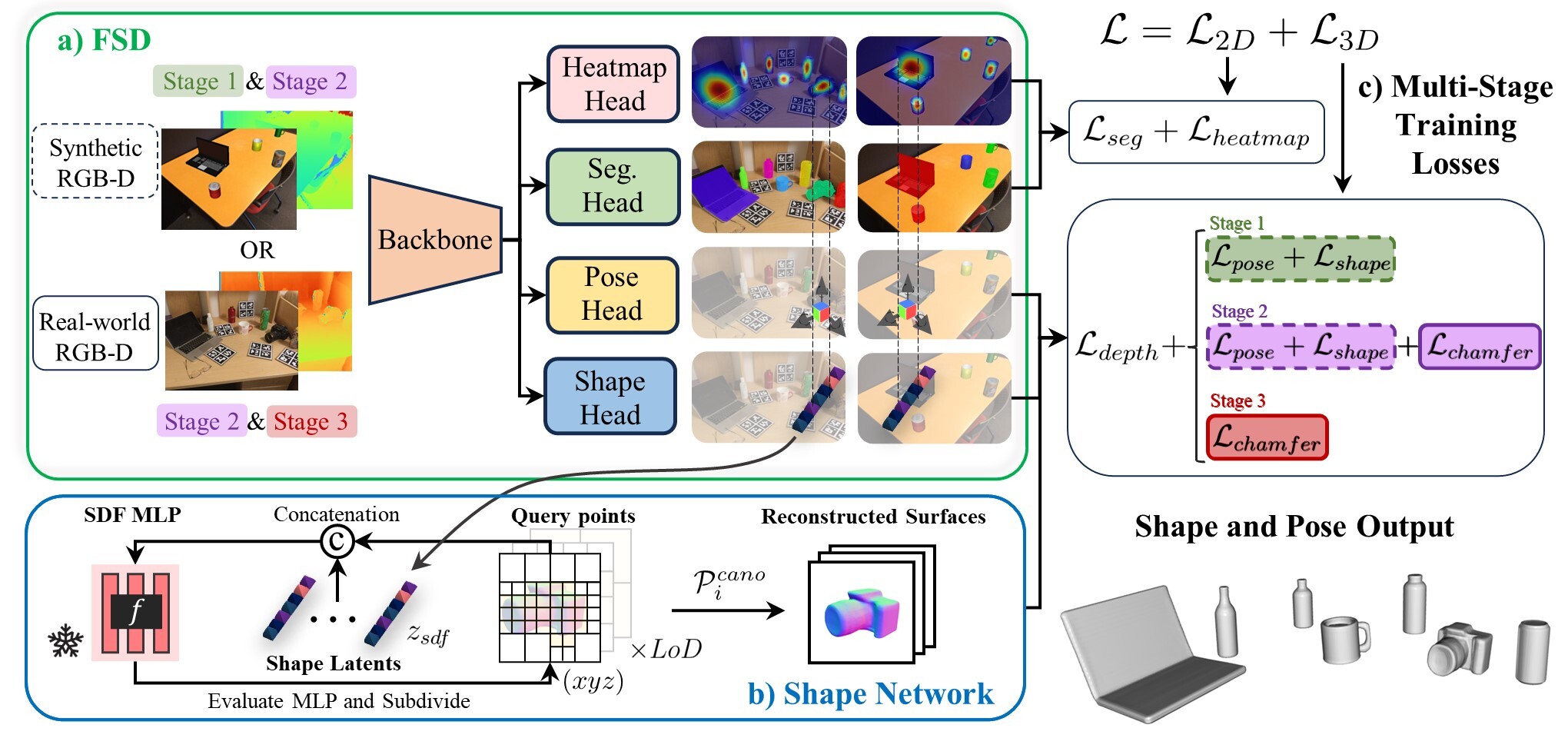
a) Forward pass of the proposed model across different training stages. From a single-view RGB-D observation, the model predicts a segmentation mask, depth map, object heatmap, pose map, and shape map. b) Batchified recursive point sampling is illustrated where the batch of concatenated 3D points and latent vectors are evaluated for SDF using a frozen shape auto-decoder. c) Losses for different training stages. Losses are color-coded based on the training stages and have solid out lines for real data and dotted lines for synthetic data.
Video
Qualitative 6D pose and size estimation comparison
Qualitative comparison: Our method vs. SSC-6D on NOCS Real275 test-set. Note that no real-world 3D labels were used for to train both methods. Our method is significantly more accurate and faster i.e. runs in near real-time at 5 Hz per image.

BibTeX
If you find our paper or pytorch code repository useful, please consider citing:
@inproceedings{lunayach2023fsd,
title={FSD: Fast Self-Supervised Single RGB-D to Categorical 3D Objects},
author={Mayank Lunayach and Sergey Zakharov and Dian Chen and Rares Ambrus and Zsolt Kira and Muhammad Zubair Irshad},
booktitle={Int. Conf. on Robotics and Automation},
organization={IEEE},
year={2024}
}